服务热线:13988889999
站内公告:
2024-04-22 14:30:04 点击量:
大多问题都可以建模成一种最优化模型进行求解,比如我们现在学习的机器学习算法,大部分的机器学习算法的本质都是建立优化模型,通过最优化方法对目标函数(或损失函数)进行优化,从而训练出最好的模型。常见的最优化方法有梯度下降法、牛顿法和拟牛顿法、共轭梯度法等等。
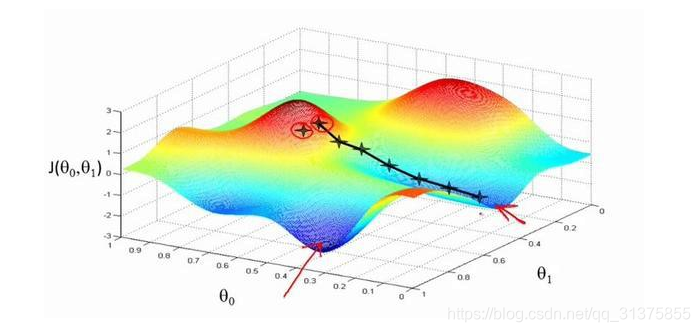
梯度下降法是最常用的一种优化算法。其核心思想是:在当前位置寻找梯度下降最快的方向,来逐渐逼近优化的目标函数。且离目标函数越近,逼近的“步伐”也就越小。梯度下降法本质是一种迭代方法,常用于机器学习算法的模型参数求解。其示意图如下图1所示:
1)牛顿法(Newton’s method)
牛顿法是一种在实数域和复数域上近似求解方程的方法。方法使用函数f (x)的泰勒级数的前面几项来寻找方程f (x) = 0的根。牛顿法最大的特点就在于它的收敛速度很快。
具体步骤:
首先,选择一个接近函数 f (x)零点的 x0,计算相应的 f (x0) 和切线斜率f ’ (x0)(这里f ’ 表示函数 f 的导数)。然后我们计算穿过点(x0, f (x0)) 并且斜率为f '(x0)的直线和 x 轴的交点的x坐标,也就是求如下方程的解:
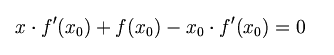
我们将新求得的点的 x 坐标命名为x1,通常x1会比x0更接近方程f (x) = 0的解。因此我们现在可以利用x1开始下一轮迭代。迭代公式可化简为如下所示:
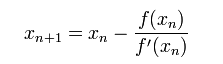
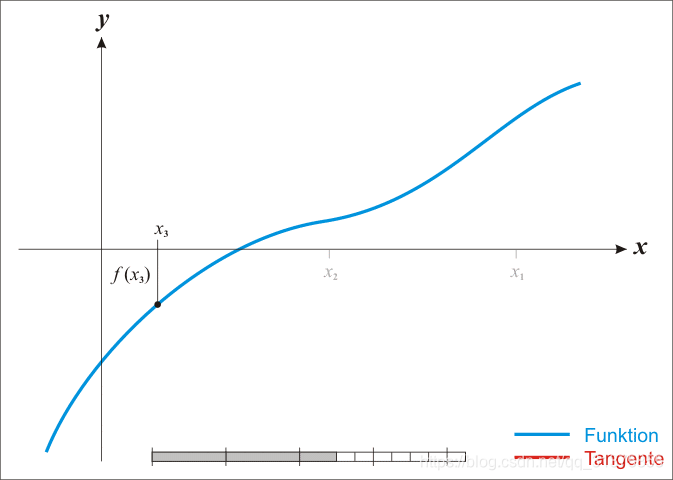
已经证明,如果f ’ 是连续的,并且待求的零点x是孤立的,那么在零点x周围存在一个区域,只要初始值x0位于这个邻近区域内,那么牛顿法必定收敛。 并且,如果f ’ (x)不为0, 那么牛顿法将具有平方收敛的性能. 粗略的说,这意味着每迭代一次,牛顿法结果的有效数字将增加一倍。下图为一个牛顿法执行过程的例子。
由于牛顿法是基于当前位置的切线来确定下一次的位置,所以牛顿法又被很形象地称为是"切线法"。牛顿法的搜索路径(二维情况)如下图所示:
牛顿法搜索动态示例图:
 关于牛顿法和梯度下降法的效率对比:
关于牛顿法和梯度下降法的效率对比:
从本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。如果更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。(牛顿法目光更加长远,所以少走弯路;相对而言,梯度下降法只考虑了局部的最优,没有全局思想。)
根据wiki上的解释,从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
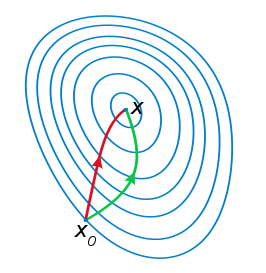
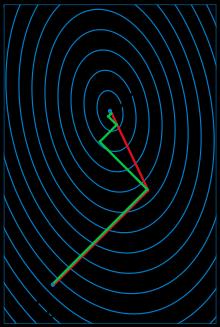
注:红色的牛顿法的迭代路径,绿色的是梯度下降法的迭代路径。
2)拟牛顿法(Quasi-Newton Methods)
拟牛顿法(柯西-牛顿法)是求解非线性优化问题最有效的方法之一,于20世纪50年代由美国Argonne国家实验室的物理学家W.C.Davidon所提出来。Davidon设计的这种算法在当时看来是非线性优化领域最具创造性的发明之一。不久R. Fletcher和M. J. D. Powell证实了这种新的算法远比其他方法快速和可靠,使得非线性优化这门学科在一夜之间突飞猛进。
拟牛顿法的本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度。拟牛顿法和最速下降法一样只要求每一步迭代时知道目标函数的梯度。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。这类方法大大优于最速下降法,尤其对于困难的问题。另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法更为有效。如今,优化软件中包含了大量的拟牛顿算法用来解决无约束,约束,和大规模的优化问题。
具体步骤:
拟牛顿法的基本思想如下。首先构造目标函数在当前迭代xk的二次模型:
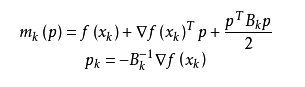
这里Bk是一个对称正定矩阵,于是我们取这个二次模型的最优解作为搜索方向,并且得到新的迭代点:
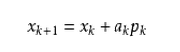
其中我们要求步长ak 满足Wolfe条件。这样的迭代与牛顿法类似,区别就在于用近似的Hesse矩阵Bk 代替真实的Hesse矩阵。所以拟牛顿法最关键的地方就是每一步迭代中矩阵Bk 的更新。现在假设得到一个新的迭代xk+1,并得到一个新的二次模型:
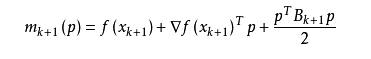
我们尽可能地利用上一步的信息来选取Bk。具体地,我们要求
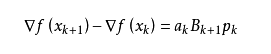
从而得到
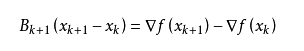
这个公式被称为割线方程。常用的拟牛顿法有DFP算法和BFGS算法。
神经网络的许多情况下,这是默认选择的算法:它比梯度下降法和共轭梯度法更快,而不需要准确计算海森矩阵及其逆矩阵。
共轭梯度法是介于最速下降法与牛顿法之间的一个方法,它仅需利用一阶导数信息,但克服了最速下降法收敛慢的缺点,又避免了牛顿法需要存储和计算Hesse矩阵并求逆的缺点,共轭梯度法不仅是解决大型线性方程组最有用的方法之一,也是解大型非线性最优化最有效的算法之一。 在各种优化算法中,共轭梯度法是非常重要的一种。其优点是所需存储量小,具有步收敛性,稳定性高,而且不需要任何外来参数。
下图为共轭梯度法和梯度下降法搜索最优解的路径对比示意图:
启发式方法指人在解决问题时所采取的一种根据经验规则进行发现的方法。其特点是在解决问题时,利用过去的经验,选择已经行之有效的方法,而不是系统地、以确定的步骤去寻求答案。启发式优化方法种类繁多,包括经典的模拟退火方法、遗传算法、蚁群算法以及粒子群算法等等。
还有一种特殊的优化算法被称之多目标优化算法,它主要针对同时优化多个目标(两个及两个以上)的优化问题,这方面比较经典的算法有NSGAII算法、MOEA/D算法以及人工免疫算法等。
有关拉格朗日乘数法的介绍请见另一篇博客:《拉格朗日乘数法》
拉格朗日乘子法主要用于解决约束优化问题,它的基本思想就是通过引入拉格朗日乘子来将含有n个变量和k个约束条件的约束优化问题转化为含有(n+k)个变量的无约束优化问题。拉格朗日乘子背后的数学意义是其为约束方程梯度线性组合中每个向量的系数。
如何将一个含有n个变量和k个约束条件的约束优化问题转化为含有(n+k)个变量的无约束优化问题?拉格朗日乘数法从数学意义入手,通过引入拉格朗日乘子建立极值条件,对n个变量分别求偏导对应了n个方程,然后加上k个约束条件(对应k个拉格朗日乘子)一起构成包含了(n+k)变量的(n+k)个方程的方程组问题,这样就能根据求方程组的方法对其进行求解。
什么是凸函数:

函数上方的点集就是凸集,函数上任意两点的连线,仍然在函数图像上方。
一句话说清楚就是:希望找到合适的x,使得f0(x)最小。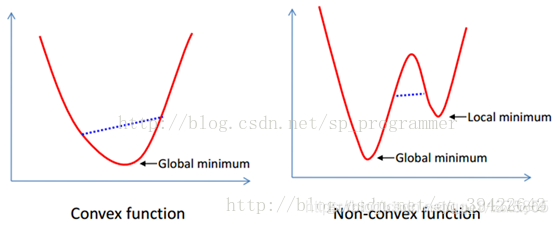
如果我们的神经网络模型有上千个参数,则可以用节省存储的梯度下降法和共轭梯度法。如果我们需要训练很多网络模型,每个模型只有几千个训练数据和几百个参数,则Levenberg-Marquardt可能会是一个好选择。其余情况下,拟牛顿法(柯西-牛顿法)的效果不错。
参考:
http://www.cnblogs.com/maybe2030/p/4751804.html
https://blog.csdn.net/qq_39422642/article/details/78816637
https://www.neuraldesigner.com/blog/5_algorithms_to_train_a_neural_network

Copyright © 2012-2018 首页-杏福娱乐-杏福商务站
地址:海南省海口市玉沙路58号电话:0898-88889999手机:13988889999
ICP备案编号:琼ICP备88889999号

微信扫一扫







